Dense Bench, Part 1: Prefill and decode curves from 4K to 128K context.
by Abhi Ram Salammagari and Koushik Salammagari
2026-05-03 · updated 2026-05-03 · 1422 words · 7 min · tags: benchmarks, mlx, llm, mac-studio, m3-ultra, dense-bench, long-context
Part 1 of the dense-bench series — see Part 0 for why this benchmark exists at all, Part 2 for the Llama 128K cliff, and Part 3 for what compressing the KV cache costs you.
Mac Studio M3 Ultra with 512 GB unified memory can fit dense 70B-class models at 4-bit quantization with ~390 GB of headroom for KV cache. The interesting question isn't can it run — it's what does the curve look like as you push context from 4K to 128K. We ran two such models — Llama-3.1-70B-Instruct-4bit and Qwen-2.5-72B-Instruct-4bit — across six prompt lengths and two prompt types via mlx-lm 0.31.2 on MLX 0.31.1. The harness is open source: see mlx-dense-bench.
Setup
| Hardware | Mac Studio M3 Ultra, 512 GB unified memory |
| OS | macOS 26.2 |
| Stack | MLX 0.31.1, mlx-lm 0.31.2, Python 3.12.13 |
| Models | mlx-community/Meta-Llama-3.1-70B-Instruct-4bit, mlx-community/Qwen2.5-72B-Instruct-4bit |
| Prompts | lorem (Moby-Dick + summarize instruction), ruler_niah (single-needle retrieval) |
| Lengths | 4K, 8K, 16K, 32K, 64K, 128K (chat-template-aware, ±2% of target) |
| Generation | 128 tokens (or until EOS), temperature 0.0, seed 42 |
| Warmup | one priming generation per (model, length, prompt) before the timed run |
Full methodology — prefill/decode split, peak-memory API selection, swap guard, library cross-check — is documented in the harness README.
Prefill throughput
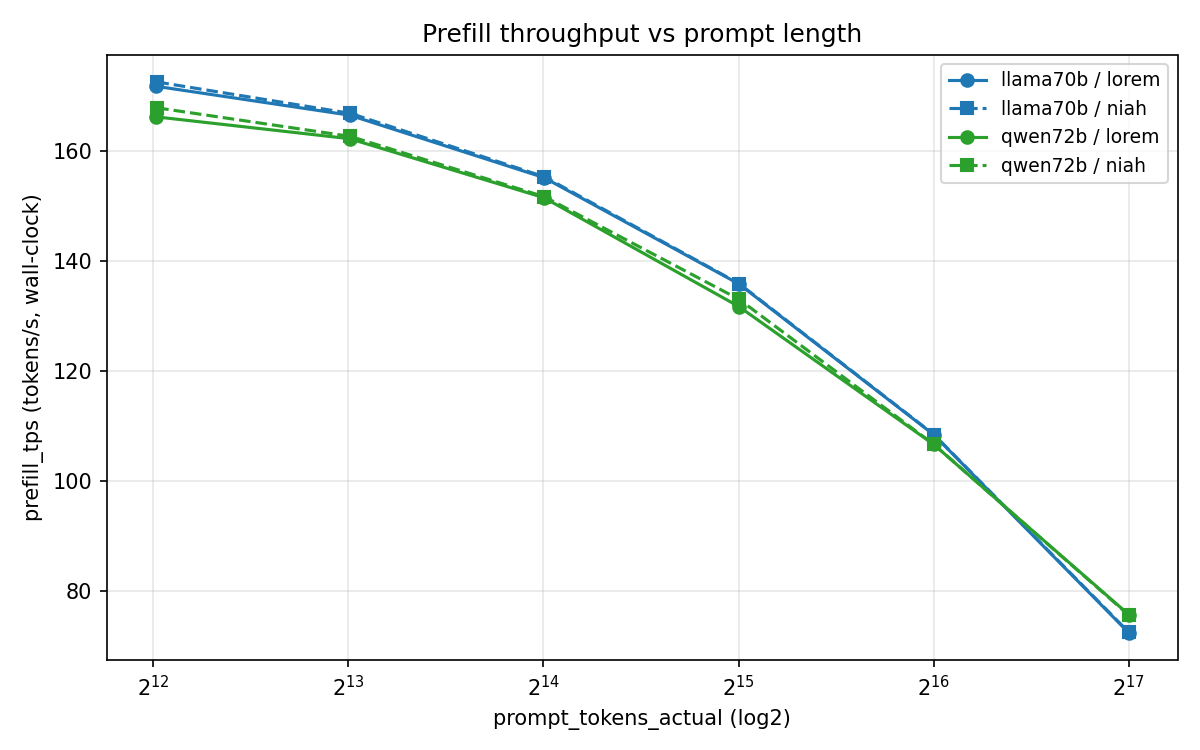
Prefill is compute-bound and degrades monotonically with context. Both models start at ~167–172 tok/s at 4K and drop to ~72–76 tok/s at 128K — a ~57% loss. The two prompt types track each other within 1% per length, which is what you'd expect for prefill (the prompt content shouldn't matter, only the length).
| length | Llama lorem | Llama niah | Qwen lorem | Qwen niah |
|---|---|---|---|---|
| 4K | 171.7 | 172.5 | 166.2 | 167.8 |
| 8K | 166.5 | 166.8 | 162.2 | 162.6 |
| 16K | 155.1 | 155.3 | 151.5 | 151.7 |
| 32K | 135.9 | 135.9 | 131.7 | 133.1 |
| 64K | 108.5 | 108.5 | 106.7 | 106.7 |
| 128K | 72.5 | 72.6 | 75.8 | 75.7 |
(All values tok/s, wall-clock.)
Time to first token
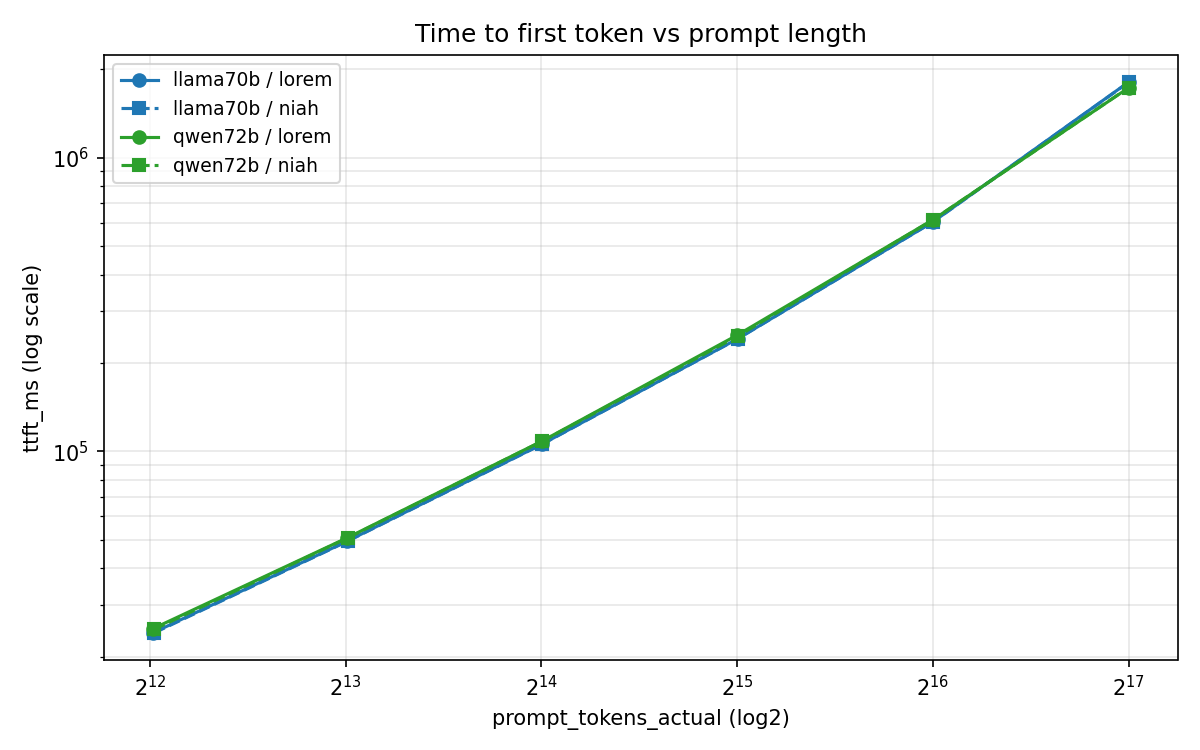
The TTFT curve is roughly straight on a log-log plot, which means TTFT scales close to quadratically with context — consistent with attention being O(n²) at prefill.
In wall-clock minutes:
| length | Llama (avg) | Qwen (avg) |
|---|---|---|
| 4K | 24 s | 25 s |
| 8K | 49 s | 51 s |
| 16K | 1.8 min | 1.8 min |
| 32K | 4.0 min | 4.1 min |
| 64K | 10.1 min | 10.2 min |
| 128K | 30.1 min | 28.9 min |
If you're building anything user-facing on top of these models at ≥64K, TTFT is the headline number. The model is busy for ten minutes before it speaks.
Decode throughput
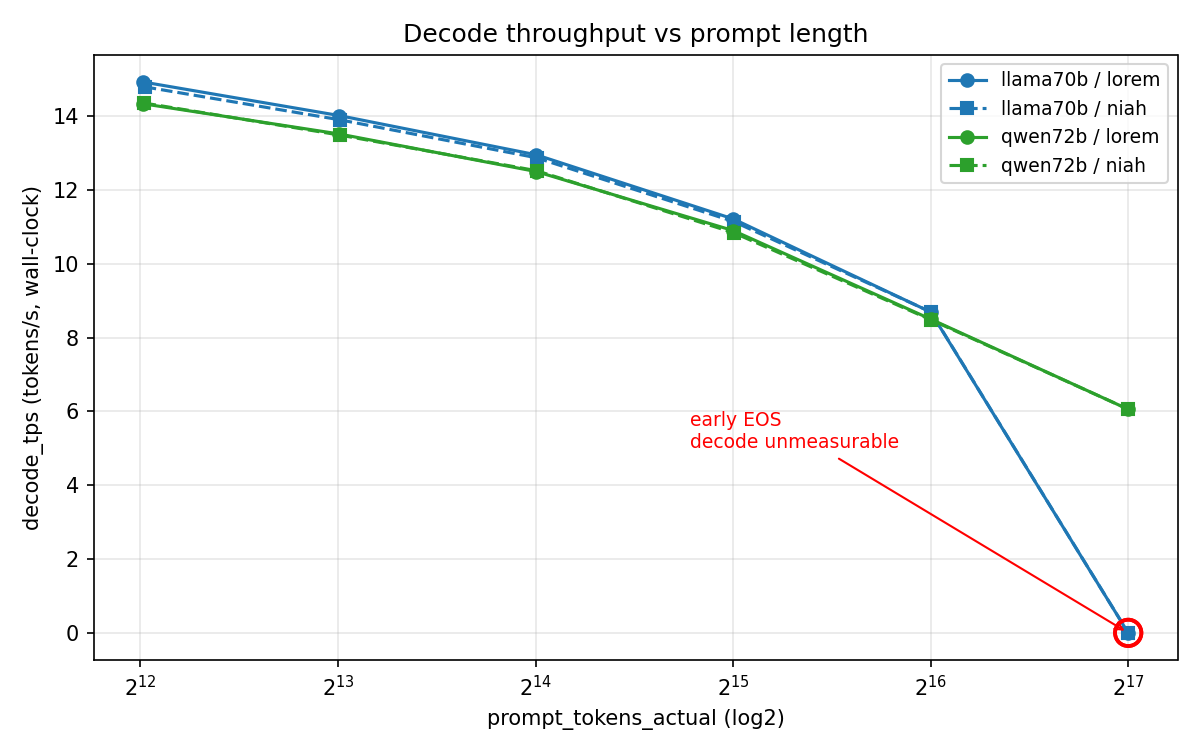
Decode is memory-bandwidth-bound: each generated token reads the full KV cache and the model weights. Cache size grows linearly with context, so decode throughput falls.
The 4K → 64K loss is essentially identical across models and prompt types (~41% drop). Qwen at 128K drops further, to 6.06 tok/s — about 42% of its 4K rate. Llama at 128K is unmeasurable (see next section).
| length | Llama lorem | Llama niah | Qwen lorem | Qwen niah |
|---|---|---|---|---|
| 4K | 14.92 | 14.79 | 14.33 | 14.35 |
| 8K | 14.01 | 13.89 | 13.51 | 13.48 |
| 16K | 12.95 | 12.87 | 12.49 | 12.52 |
| 32K | 11.21 | 11.14 | 10.89 | 10.84 |
| 64K | 8.69 | 8.69 | 8.50 | 8.48 |
| 128K | — (EOS) | — (EOS) | 6.06 | 6.06 |
Two early notes from the table:
- Llama and Qwen decode rates differ by less than 5% per row at matched context. Different architectures, same memory-bandwidth ceiling.
- Lorem and niah differ by less than 0.5% per (model, length) cell. The prompt content doesn't change decode cost — only the cache size does.
The Llama 128K cliff
At 128K context, both Llama runs (lorem and niah) emit <|eot_id|>
as the first generated token. Generation length = 1, decode_tps = 0.
Qwen produces 99 (lorem) and 128 (niah) tokens at the same length.
This is real model behavior. The harness flagged the rows
(early_eos=True, valid_decode=False) and excluded them from the
decode plot. Mechanism is unconfirmed but consistent with attention
collapse at the very edge of the model's training context window —
Llama-3.1-70B-Instruct's nominal context limit is exactly 128K
tokens, and our prompts run a hair over (131,114 and 131,133 tokens
including chat template). Qwen-2.5-72B-Instruct nominally supports
128K natively without RoPE scaling and absorbs the extra without
trouble.
The TTFT and prefill numbers for Llama 128K are valid (the prefill pass completed; the model just chose to stop immediately). They're useful for reasoning about where you can put a long-context Llama prompt without the model giving up.
Memory
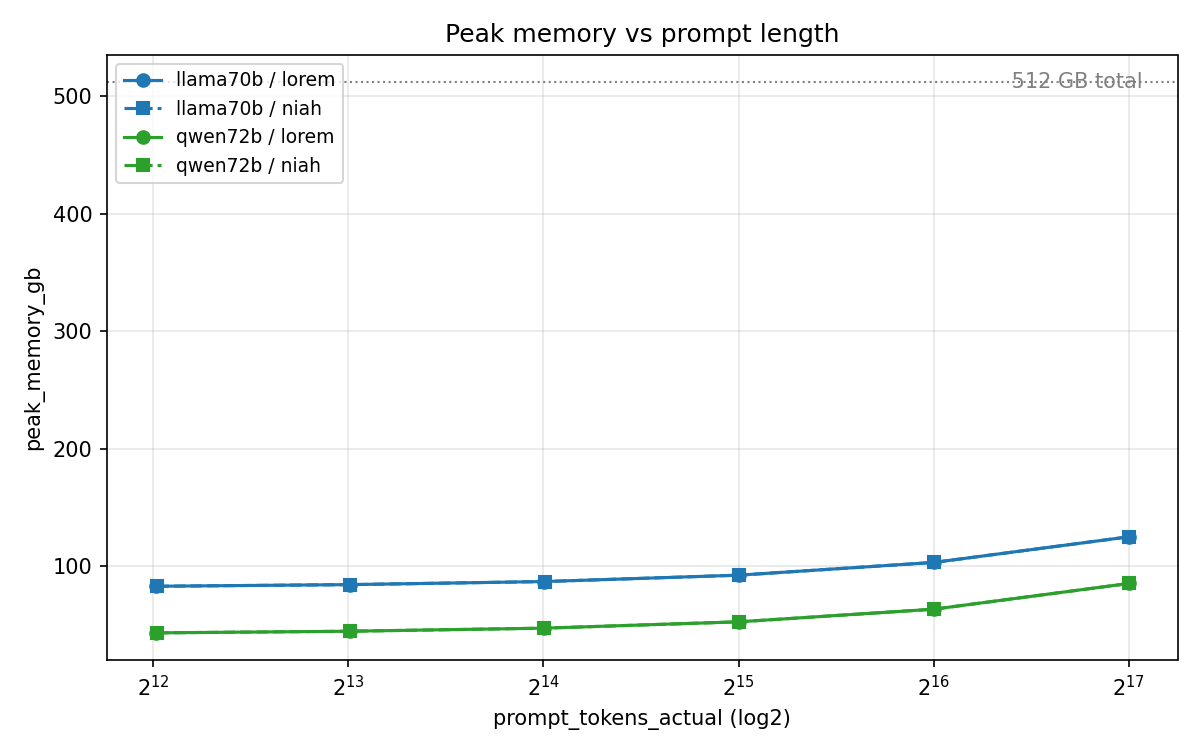
Even at 128K context, both models sit comfortably under 25% utilization of the 512 GB ceiling. KV cache and activation overhead grow modestly with context — Llama goes from 83 GB (4K) to 125 GB (128K), Qwen from 43 GB (4K) to 85 GB (128K). Qwen's smaller footprint reflects its grouped-query attention with fewer KV heads.
The takeaway: M3 Ultra 512 GB is not close to the working-set limit for dense 70B-class models at 128K. The bottleneck for going larger or longer is compute time, not RAM.
Methodology notes (quick)
- Prefill/decode split at the first emitted token (wall-clock).
- Wall-clock as primary; mlx-lm internal timings reported as cross-check. Median delta on these runs: 0.05%.
- Peak memory captured per-run via the MLX peak-memory API
(
mx.get_peak_memory+ reset before each run). suspect_swapflag fires when decode falls below 0.5 tok/s and the row isn't already marked early-EOS. No row in this matrix triggered it after the early-EOS gating fix.- Prompts are length-trimmed at the token level (not by string slicing) using each model's own tokenizer, with the chat template applied. Actual lengths land within +0.5% of target.
Full notes in the harness README.
Reproducing
The runner is resumable: rows already in results/matrix.jsonl
(matched by config hash) are skipped, so you can Ctrl-C and pick
up where you left off.
What's not in this post
- The full RULER 13-task suite. Only single-needle (NIAH) is exercised here — long-context retrieval quality is a separate experiment from throughput.
- Speculative decoding, batching, or any serving-stack optimizations. Single-stream, single-prompt only.
- 8-bit or full-precision variants. 4-bit is what fits without forcing trade-offs at 128K.
Citation
@misc{salammagari2026mlxdensebench,
author = {Salammagari, Abhi Ram and Salammagari, Koushik},
title = {Dense 70B in MLX on M3 Ultra 512GB: prefill and decode
curves from 4K to 128K context},
year = {2026},
url = {https://github.com/abhiram304/mlx-dense-bench}
}
~~~