Dense Bench, Part 3: Compressed KV at the retrieval boundary.
2026-05-12 · updated 2026-05-17 · 3204 words · 16 min · tags: benchmarks, mlx, llm, mac-studio, m3-ultra, dense-bench, kv-cache, quantization, llama, qwen
Part 3 of the dense-bench series. Part 0 is the why; Part 1 is the numbers; Part 2 is the Llama 128K cliff.
Part 1 established that M3 Ultra 512GB is compute-bound, not
memory-bound, at dense 70B and 128K context. Part 2 found
that retrieval breaks earlier than the hardware ceiling — Llama
collapses at 96K, Qwen retains only at back-half depths at 128K, both
under full-precision FP16 KV. The natural next question is what KV
compression costs on top of that. Most published work on Apple Silicon
KV-quant (Open-TQ-Metal, TurboQuant variants in mlx-lm) targets 64 GB
consumer hardware where compression is a necessity and the FP16
baseline cannot run. On 512 GB, FP16 KV at 128K is feasible, which
makes int8 and int4 a choice whose retrieval cost is measurable
against an actual baseline.
The headline of this post is simpler than I expected before running
the matrix. Under mlx-lm 0.31.2's affine QuantizedKVCache with
quantized_kv_start=0 (i.e. quantize from prompt token 0, which is
what saves prompt-KV memory in the first place), the failure boundary
is dominated by context length. The bit-width axis collapses
entirely: int8 and int4 behave identically on Llama, and nearly
identically on Qwen. The model axis is real and large: Llama has a
hard cliff at 32K → 64K, Qwen has a softer 64K boundary with a clean
depth structure before falling off the same cliff at 96K. Reframe the
question from "where does compression break retrieval?" to "length
breaks retrieval under naïve affine KV-quant; bit width is a rounding
error."
Setup
| Hardware | Mac Studio M3 Ultra, 512 GB unified memory |
| OS | macOS 26.2 |
| Stack | MLX 0.31.1, mlx-lm 0.31.2, Python 3.12.13 |
| Models | mlx-community/Meta-Llama-3.1-70B-Instruct-4bit, mlx-community/Qwen2.5-72B-Instruct-4bit |
| Prompt type | ruler_niah (single-needle retrieval) |
| Lengths (main matrix) | 4K, 16K, 32K, 64K, 96K (Llama); 4K, 16K, 32K, 64K, 96K, 112K, 128K (Qwen) |
| Depths | 0.1, 0.3, 0.5, 0.7, 0.9 (fraction of corpus body) |
| KV precisions | int8, int4 (affine QuantizedKVCache, group_size=64, quantized_kv_start=0) |
| FP16 baseline | reused from Part 2's results/niah_depth.jsonl |
| Generation | 128 tokens (or until EOS), temperature 0.0, seed 42 |
| Warmup | one priming generation per (model, length, depth, kv_bits) |
| Answer-check | substring match for "47293" in full_text |
Same hardware and software stack as Parts 1 and 2. What's new is the
kv_bits / kv_group_size / quantized_kv_start plumbing in
bench.py and runner.py, the four new fields in the row schema
(also rope_scaling_factor), and analysis/plot_post3.py for the
three-precision panels. Results go to results/post3.jsonl, separate
from Part 1's results/matrix.jsonl
and Part 2's
results/niah_depth.jsonl. Part 1 and Part 2 artifacts are untouched.
Method
A run is marked correct if the string "47293" appears anywhere in
the model's full generated response. Greedy decoding
(temperature=0.0) makes each cell deterministic. The KV-quant code
path is mlx-lm's stream_generate(..., kv_bits=N, kv_group_size=64, quantized_kv_start=0), which engages the affine
QuantizedKVCache from prompt token 0. This is the most aggressive
setting — quantizing only generated tokens (quantized_kv_start = prompt_length) would leave the prompt KV at FP16 and is a different
experiment (one that compresses nothing if generation is short).
The matrix was reduced mid-run after the validation gate revealed two
things. First, Llama at 64K under int8 KV completely fails to
retrieve, with the same answer-checked failure mode at every depth
and bit width — there is no boundary to map within Llama past 64K, so
running Llama 112K and 128K would have produced 20 more all-fail
cells at ~30 hours of compute for no new information. Second, the
192K Llama probe-validation cell produced degenerate output even at
FP16 KV (". The is was a. The is of be the."). Post-publication
review found the probe cell ran on native-RoPE Llama 70B (its config's
own rope_scaling.factor=8, native max_position_embeddings=131072)
fed a 196K-token prompt, not on the rope_scaling.factor=12.0
override variant the runner intended (a cache-key bug in bench.py
that let an earlier non-override load shadow the override; fixed in a
follow-up commit). Either way — naïve overflow past trained context
or RoPE 1.5× extrapolation, both at FP16 KV — the cell was degenerate;
running KV-quant variants on top of an already-degenerate FP16 base
adds nothing. Both threads (the Llama 112K/128K cells and the entire
192K probe) were dropped from the matrix and are recorded as such here
rather than papered over.
Results
Llama-3.1-70B-Instruct-4bit (0 / 50 quant cells correct past 32K)
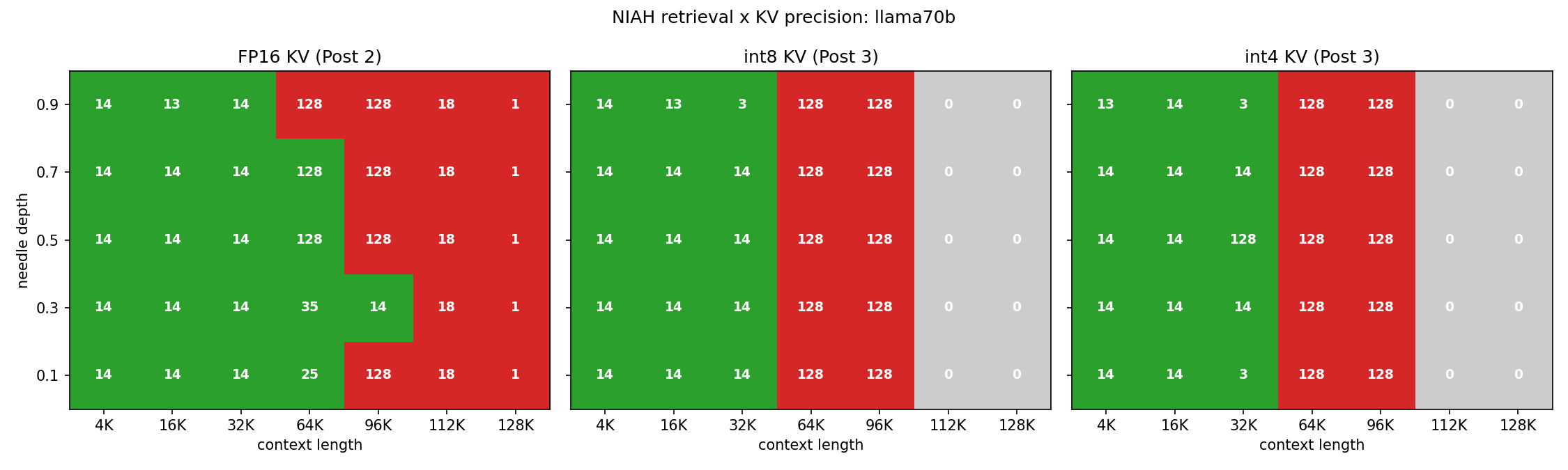
| 4K | 16K | 32K | 64K | 96K | |
|---|---|---|---|---|---|
| kv8 d=0.1 | ✓ | ✓ | ✓ | ✗ | ✗ |
| kv8 d=0.3 | ✓ | ✓ | ✓ | ✗ | ✗ |
| kv8 d=0.5 | ✓ | ✓ | ✓ | ✗ | ✗ |
| kv8 d=0.7 | ✓ | ✓ | ✓ | ✗ | ✗ |
| kv8 d=0.9 | ✓ | ✓ | ✓ | ✗ | ✗ |
| kv4 d=0.1 | ✓ | ✓ | ✓ | ✗ | ✗ |
| kv4 d=0.3 | ✓ | ✓ | ✓ | ✗ | ✗ |
| kv4 d=0.5 | ✓ | ✓ | ✓ | ✗ | ✗ |
| kv4 d=0.7 | ✓ | ✓ | ✓ | ✗ | ✗ |
| kv4 d=0.9 | ✓ | ✓ | ✓ | ✗ | ✗ |
Llama retrieves perfectly at 4K, 16K, and 32K under both int8 and int4 KV. At 64K and 96K, every single cell fails, regardless of bit width or depth. The output is uniformly degenerate — the model gets stuck in a single token-level loop and writes the same fragment over and over:
Llama 70B, int8 KV, 64K context, needle at d=0.5: "The first, the first, the first, the first, the first, the first, the first, the first, the first, the first…"
The kv4 column is byte-identical at the cell level (same pass/fail pattern) and qualitatively identical (same kind of degenerate loops). The diff view confirms this: every Llama cell at 64K and 96K shows up as "quant lost retrieval" relative to Part 2's FP16 baseline — there are no cells where int8 retrieved but int4 didn't, nor any where int4 found something int8 missed.
Qwen-2.5-72B-Instruct-4bit (35 / 70 quant cells correct)
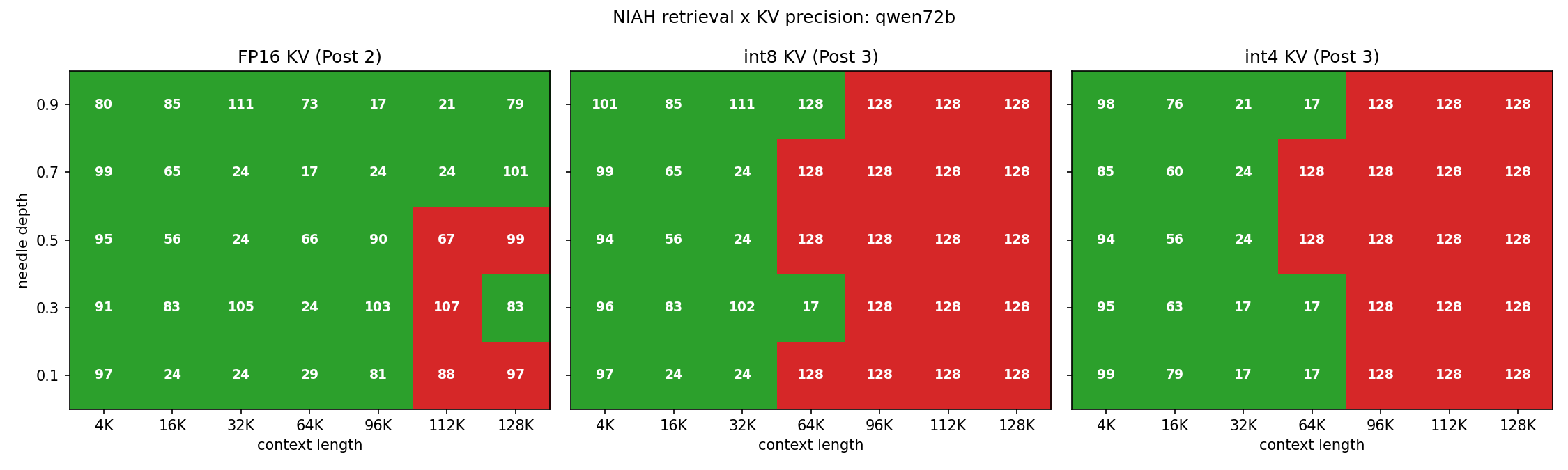
| 4K | 16K | 32K | 64K | 96K | 112K | 128K | |
|---|---|---|---|---|---|---|---|
| kv8 d=0.1 | ✓ | ✓ | ✓ | ✗ | ✗ | ✗ | ✗ |
| kv8 d=0.3 | ✓ | ✓ | ✓ | ✓ | ✗ | ✗ | ✗ |
| kv8 d=0.5 | ✓ | ✓ | ✓ | ✗ | ✗ | ✗ | ✗ |
| kv8 d=0.7 | ✓ | ✓ | ✓ | ✗ | ✗ | ✗ | ✗ |
| kv8 d=0.9 | ✓ | ✓ | ✓ | ✓ | ✗ | ✗ | ✗ |
| kv4 d=0.1 | ✓ | ✓ | ✓ | ✓ | ✗ | ✗ | ✗ |
| kv4 d=0.3 | ✓ | ✓ | ✓ | ✓ | ✗ | ✗ | ✗ |
| kv4 d=0.5 | ✓ | ✓ | ✓ | ✗ | ✗ | ✗ | ✗ |
| kv4 d=0.7 | ✓ | ✓ | ✓ | ✗ | ✗ | ✗ | ✗ |
| kv4 d=0.9 | ✓ | ✓ | ✓ | ✓ | ✗ | ✗ | ✗ |
Qwen has the same flat-perfect block at 4K, 16K, and 32K. At 64K something more interesting happens: retrieval splits along depth. The edge depths d=0.3 and d=0.9 retrieve cleanly under both int8 and int4. The middle depths d=0.5 and d=0.7 fail. d=0.1 sits between — int4 retains, int8 does not. From 96K onward, the pattern flattens out and every cell fails, matching Llama. Bit width still does not matter: the int8 and int4 columns at 64K agree on 4 of 5 depths and disagree only at d=0.1.
Two failure modes are worth quoting because they're qualitatively different from Llama's repetition loops. Qwen produces plausible wrong answers:
Qwen 72B, int8 KV, 64K context, needle at d=0.5: "The magic number for Aardvark is 42. To find the magic number for Aardvark, we need to determine the value of \(a\) such that the equation 42a + 42 = 2023. Solving for \(a\): 42a + 42 = 2023. Subtract 42 from both sides…"
The model retrieves a Hitchhiker's Guide reference, then attempts to derive 42 with a fabricated algebraic identity. It is confidently wrong, in a different way than Llama's degenerate looping is confidently wrong.
At long context, Qwen drifts toward token salad:
Qwen 72B, int4 KV, 128K context, needle at d=0.9: "I'm trying to the / of the / the same as the / of the / the / of the / to the / of the…"
This is a striking regression against the FP16 baseline. There, Qwen retained retrieval at d=0.9 even at 128K — visible in the FP16 cells from Part 2's run, even though Part 2's prose stayed on the Llama cliff. Compressing the KV to int8 or int4 destroys that retention. The d=0.9 cells at 128K are no longer special.
Differential view: where KV-quant cost retrieval
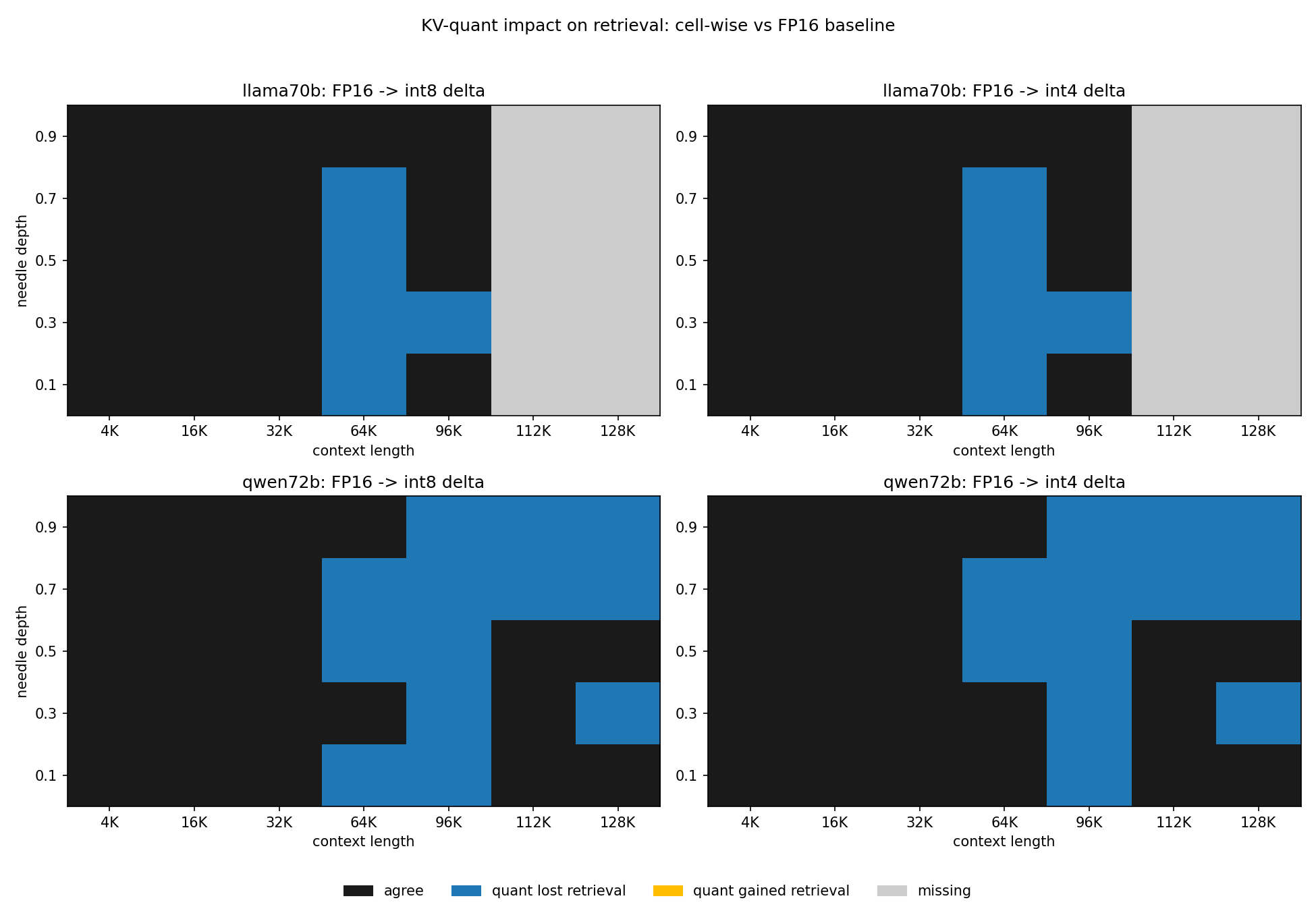
The diff view makes the headline visible at a glance. Every dark blue cell is a (model, length, depth) where FP16 KV retrieved and the quantized variant did not. There are no gold cells (quant gained something FP16 lost) in either model. The Llama 70B panels show a sharp horizontal band of blue from 64K onward — KV-quant destroys everything past 32K. The Qwen 72B panels show a more textured pattern at 64K (depth-dependent losses), then full blue from 96K onward.
What broke and what didn't
The most interesting non-finding is that bit width doesn't matter.
The expectation from prior work on KV quantization is that int4 is
substantially more aggressive than int8 and should produce
correspondingly larger retrieval losses. That is not what these data
show. Under affine QuantizedKVCache with quantized_kv_start=0,
the boundary at which retrieval fails is determined by context
length and (for Qwen) by depth structure within that boundary. Once
context exceeds the model-specific threshold, the cache is too
information-poor to support retrieval at either bit width.
A related non-finding is on memory. The plan assumed that engaging
KV-quant would reduce peak memory at long context — that's the
whole point of compression. In mlx-lm 0.31.2 it does not. The
prompt KV is built at full precision first, then to_quantized is
called on each layer's cache once quantized_kv_start is reached,
which means both representations exist transiently. At 64K Llama 70B
the FP16 cell peaked at 62.2 GB; the int8 cell peaked at 79.1 GB; the
int4 cell at 80.9 GB — higher, not lower. Steady-state memory after
the conversion is reduced (the FP16 cache is freed), but the peak is
not what end-users see decrease. This matters for the 64 GB-Mac
audience that quantization is supposed to serve: if peak briefly
exceeds RAM, the run OOMs regardless of bit width. (On 512 GB the
peak is comfortably under the ceiling.)
Wall-clock cost also moved against KV-quant. The validation gate
measured FP16 at 64K Llama at 20 min/cell (warmup + timed). int8 at
the same cell was 32 min. int4 was 31 min. The 50–60% overhead is
the cost of per-step maybe_quantize_kv_cache and quantized-attention
in the absence of compressed-domain attention kernels (the very
problem Open-TQ-Metal's Metal-shader work targets). For the matrix,
that overhead is paid on every cell.
What we're not claiming
- This is not a critique of KV quantization in general. The
result is specific to
mlx-lm0.31.2's affine 4/8-bitQuantizedKVCachewith the prompt-timequantized_kv_start=0configuration. Different quantization schemes (TurboQuant / PolarQuant 3-bit; Open-TQ-Metal's fused compressed-domain attention; KVQuant's per-token mixed precision) would likely show different boundaries. The headline is about the path that's currently available in mlx-lm out of the box, not about quantization-in-principle. - This is not a claim about whether int8 KV is "safe." Single- needle NIAH is a narrow probe. Models can retain enough perplexity to look fluent on free-form text while losing the specific lookup needed for retrieval. The opposite is also possible. NIAH is a forcing function for retrieval; it is not a substitute for downstream task evaluation.
- The 192K probe was attempted but not deployed. A single
preflight cell at 192K Llama produced degenerate output. The
load-time
model_config={"rope_scaling.factor": 12.0, ...}override propagates correctly tomodel.args.rope_scaling(verified on Qwen-1.5B before launch), but a separate cache-key bug inbench.py— fixed in a follow-up commit on this branch — meantrun_benchmark's internal_load_model(path)call cache-hit the previously-loaded un-overridden Llama instance instead of the override variant. The probe-validation cell therefore ran on native-RoPE Llama at a 196K-token prompt (overflow pastmax_position_embeddings=131072), not on the RoPE-12 override. Either way the cell was degenerate at FP16 KV; running KV-quant variants on top adds nothing. A proper "beyond 128K" study would need to fix the harness and either fine-tune position- interpolation on long sequences or evaluate a model that's been trained for longer context natively. - The Llama 70B matrix was not run at 112K or 128K under
KV-quant. After the 64K and 96K cells produced uniform failure
with no depth or bit-width structure, the marginal information
value of running 20 more confirmation cells did not justify the
~30 hours of additional compute. The columns are intentionally
blank in
niah_kv_quant_llama70b.png. If a future post argues that something changes at Llama 112K under affine KV-quant, someone should run those cells — but I do not expect them to. - Single needle, single phrasing, single seed. Same convention and same disclosure as Part 2.
Comparison to prior art
The closest precedent is Open-TQ-Metal (arXiv 2604.16957), which
implements fused compressed-domain attention for Apple Silicon and
runs Llama 70B at 128K on a 64 GB Mac. Their evaluation criterion is
top-1 token agreement with FP16, not answer-checked retrieval; this
post evaluates retrieval directly. The closest match in retrieval
methodology is TurboQuant (ICLR 2026; also a mlx-lm issue
thread), which validates KV-quant down to 3-bit with NIAH at 6/6
exact retrieval — but not on dense 70B at the length boundary, and
with a non-affine quantization scheme. The closest match in model
families is the EMNLP 2025 Findings paper "Does quantization affect
models' performance on long-context tasks?", which evaluates the
exact two model families used here (Llama 3.1 8B/70B, Qwen 2.5
7B/32B/72B) at ≥64K with five weight-quantization methods — the
finding there ("4-bit methods lose up to 59% on long-context tasks")
is about weight quantization, not KV cache quantization.
What this post adds, narrowly: an answer-checked retrieval boundary
on Apple Silicon at dense 70B as a function of KV-cache bit width,
with an FP16 baseline that consumer-Mac hardware cannot run. The
finding — that the bit-width axis collapses in favour of a hard
length cliff under mlx-lm's affine QuantizedKVCache — is consistent
with the literature's motivation for non-affine schemes
(TurboQuant, KVQuant) and with Open-TQ-Metal's argument that fused
compressed-domain attention is what makes KV-quant viable at long
context. The 512 GB hardware is what made the comparison possible.
Reproducing
git clone https://github.com/abhiram304/mlx-dense-bench
cd mlx-dense-bench
python -m venv .venv && source .venv/bin/activate
pip install -r requirements.lock
# weights (~80 GB combined, ~30 min on a fast connection)
hf download mlx-community/Meta-Llama-3.1-70B-Instruct-4bit
hf download mlx-community/Qwen2.5-72B-Instruct-4bit
# Part 2 FP16 baseline (~28 hours on M3 Ultra 512GB) — required for
# the final plot step, which joins this against Part 3's quant cells.
# Skip if you've already run Part 2 and have results/niah_depth.jsonl.
python runner.py configs/niah_depth.json results/niah_depth.jsonl
# Part 3 validation gate (~3 hours, runs 4 cells incl. 192K RoPE probe)
python runner.py configs/post3_validation.json results/post3_validation.jsonl
pytest tests/test_validation_post3.py -v
# Part 3 main matrix (~50 hours on M3 Ultra 512GB, resumable)
python runner.py configs/post3_main.json results/post3.jsonl
python runner.py configs/post3_qwen_resume.json results/post3.jsonl
# heatmaps and CSV (joins Part 2 FP16 with Part 3 quant cells)
python -m analysis.plot_post3 \
--fp16 results/niah_depth.jsonl \
--post3 results/post3.jsonl \
--figs analysis/figs \
--tables analysis/tables
The runner is resumable: rows already in results/post3.jsonl
(matched by config_hash, which includes kv_bits,
kv_group_size, quantized_kv_start, and rope_scaling_factor)
are skipped. First Ctrl-C finishes the current cell and exits
cleanly; second Ctrl-C exits immediately.
The Llama 112K and 128K cells are intentionally not in
configs/post3_main.json — that's the mid-run scope trim. The
configs/post3_probe192k.json and configs/post3_repro_audit.json
files exist in the repo but were not run; they are kept for
completeness and can be revisited.
Colophon
| Hardware | Mac Studio M3 Ultra, 512 GB unified memory |
| OS | macOS 26.2 |
| Python | 3.12.13 |
| MLX | 0.31.1 |
| mlx-lm | 0.31.2 |
| Models | mlx-community/Meta-Llama-3.1-70B-Instruct-4bit, mlx-community/Qwen2.5-72B-Instruct-4bit |
| KV-quant config | affine QuantizedKVCache, group_size=64, quantized_kv_start=0 |
| Matrix size | 120 cells (50 Llama, 70 Qwen) + 4 validation cells |
| Wall-clock | ~73 hours end-to-end (initial Llama run + Qwen resume) |
| Dates | matrix start 2026-05-08, matrix end 2026-05-11 |
| License | see LICENSE in the public repo |
| Public artifacts | github.com/abhiram304/mlx-dense-bench (harness, configs, results JSONL, figures, joined CSV) |
Part 2's FP16 baseline
data (results/niah_depth.jsonl) is reused without modification under
the same MLX / mlx-lm version pin. A sanity-check cell at 64K Llama
d=0.5 reproduced Part 2's "47293" answer byte-for-byte before the
matrix launched.
Citation
@misc{salammagari2026densebench3,
author = {Salammagari, Abhi Ram},
title = {Dense Bench, Part 3: Compressed KV at the retrieval boundary},
year = {2026},
url = {https://www.abhiramsalammagari.com/writing/dense-bench-3-compressed-kv-at-the-retrieval-boundary},
note = {harness: \url{https://github.com/abhiram304/mlx-dense-bench}}
}
~~~