Dense Bench, Part 4: Memory doesn't predict it — agentic reliability vs quantization.
by Salammagari, Abhi Ram and Salammagari, Koushik
2026-06-24 · updated 2026-06-24 · 3300 words · 17 min · tags: benchmarks, mlx, llm, mac-studio, m3-ultra, dense-bench, agents, tool-calling, quantization, llama, qwen
Part 4 of the dense-bench series. Part 0 is the why; Part 1 is the throughput numbers; Part 2 is the Llama 128K cliff; Part 3 is compressed KV at the retrieval boundary.
Parts 1–3 measured what a model can hold (throughput, memory) or read (retrieval). This one measures whether it can act — multi-turn tool-calling, graded on whether the agent finishes the end-to-end job, not whether a single tool call happens to parse.
The one-paragraph version
I gave two AI assistants — two real language models, Qwen and Llama — the exact same set of computer-filing chores: move this file here, copy that one there, don't touch the thing you weren't asked to touch. I ran each chore twenty times, so I could see how consistent each one was, not just whether it got lucky once. Then I varied the thing people actually argue about: I ran each assistant at two compression settings — one squeezed a little (uses more memory), one squeezed harder (uses less) — to see whether squeezing it costs reliability. Two surprises. First, comparing the two assistants, the one using more memory was not the more reliable one — the smallest, cheapest setup was the worst. Second, squeezing helped one assistant and hurt the other. The common advice — "use the bigger, higher-quality version if you care about reliability" — was simply wrong for one of the two.
What the words mean
- An AI agent / tool-calling. Instead of just chatting, the AI is allowed to do things — run commands like "list the files," "change folder," "copy this." A task is only a success if the whole sequence ends with the computer in the right final state. Getting one step right doesn't count; finishing the job does.
- Quantization (the "shrinking"). A big AI model is a giant pile of numbers. You can store those numbers at high precision (more memory, slower to load) or round them off to save space. "4-bit" is more aggressive rounding than "8-bit." Think of it like a JPEG: you can save a photo at full quality or compress it. The question is whether the compressed version still does the job.
- Memory. How much of the computer's RAM the model needs while it works. More memory costs money and isn't free — so if a smaller version is just as reliable, the bigger one is wasted money.
What I found, plainly
- Memory didn't predict reliability. The two most-squeezed versions used almost the same amount of memory, yet one finished the job five times as often as the other. The cheapest, smallest setup was the worst one. If you'd picked your model by "how fast is it / how little memory does it use," you'd have picked the least reliable one.
- Shrinking helped one, hurt the other. For one model (Qwen), the more compressed version was actually a bit more reliable — and far cheaper on memory. For the other model (Llama), compressing it made it noticeably worse. Same exact change, opposite results. There is no universal "more precision is safer" rule.
- Why the Llama one got worse when compressed. The compressed Llama had a habit of getting stuck — calling the same tool over and over in a loop, like a person repeatedly trying the same wrong key in a lock. Giving it more precision mostly cured the stuck-in-a-loop problem and turned those total failures into near-misses (right idea, small mistake).
- The single most common mistake was the assistant forgetting to "change into the right folder" before acting — so it did the right thing in the wrong place. Roughly four out of five of the near-misses were exactly this one slip.
- Most of the hard tasks, both assistants simply couldn't do. Five of the eight chores were failed by every version — and even the best setup finished only about a quarter of all the chores. None of these is reliable at this yet; the point is which is less unreliable, and why the usual specs don't predict it. I'm reporting that honestly rather than hiding it — the interesting differences showed up on the two tasks that were hard-but-doable.
Why this matters for a normal person
If you're choosing or paying for an on-device AI, the specs everyone quotes — speed, memory footprint — do not tell you whether it will actually finish your task. A setup can look great on a benchmark and be the least reliable in practice. And "buy the bigger, higher-quality version" is not a safe default: sometimes the smaller one is both cheaper and more reliable. The only way to know is to test the actual job, many times, and count how often it finishes — which is the whole point of this series.
Want the receipts — the exact tasks, numbers, failure breakdowns, and how it was measured? Flip the switch above to Full technical.
The question is the one arXiv 2505.19433 ("Can Compressed LLMs Truly Act?") asks for ≤32B models on T-Eval-style competency: does weight quantization change agentic reliability? We extend it to the large-model / MLX / end-to-end-completion regime, at a fixed unified-memory budget where 4-bit and 8-bit are both a choice, not a necessity.
The headline is more interesting than "8-bit is safer." Across two families at two bit widths, memory does not predict reliability, and the quant→reliability effect flips by model family: 4-bit beats 8-bit for Qwen, 8-bit beats 4-bit for Llama. The single number that exposes it is pass^k (probability all k runs of a config × task succeed) — per-run accuracy looks close where pass^5 is 3× apart.
Setup
| Hardware | Mac Studio M3 Ultra, 512 GB unified memory |
| OS | macOS 26.2 (arm64) |
| Runtime | mlx 0.31.1, mlx-lm 0.31.2 |
| Models | Qwen-2.5-72B-Instruct, Llama-3.1-70B-Instruct |
| Quant | self-built via mlx_lm.convert from base HF weights, affine, group size 64 |
| Task suite | BFCL v4 multi-turn (gorilla 6ea5797), GorillaFileSystem-only, 8 tasks |
| Sampling | temperature 0.7, seeds 0–19 (same set across all configs) |
| Runs | 20 per (config × task); 640 episodes total |
The four quant artifacts were built locally so 8-bit vs 4-bit differ only in bit width (same base weights, same group size, same affine mode), with the exact convert command and a SHA-256 over the weight shards recorded per artifact:
| artifact | bits | on-disk | served peak |
|---|---|---|---|
qwen72b-4bit | 4 | 40.9 GB | 48 GB |
qwen72b-8bit | 8 | 77.3 GB | 84 GB |
llama70b-4bit | 4 | 39.7 GB | 42 GB |
llama70b-8bit | 8 | 75.0 GB | 78 GB |
Only the two 4-bit configs land in the ~40–55 GB band; the 8-bit configs sit near 80 GB. That asymmetry is the point — if 8-bit doesn't buy reliability, it is paying ~1.75× the memory for nothing.
Method
The reliability layer, not the throughput layer. Throughput / TTFT / peak memory come from the dense-bench harness (Parts 1–3). This post adds an agent loop on top and grades task completion: did the agent finish the end-to-end job. We never report single-call accuracy as "reliability."
One identical harness, only the model swaps. Each model is loaded in-process (reusing the dense-bench loader) and generated with stream_generate on a client-side-applied chat template; the system prompt, tool definitions, decoding params, and seed set are byte-identical across all four configs. We deliberately do not route through mlx_lm.server: its OpenAI endpoint parses and strips tool calls from the model output (and crashes on malformed tool JSON), which would lose the raw output we are required to log. In-process generation returns the model's raw text every turn. (See What broke — this was a mid-project pivot.)
Determinism, and why temperature 0.7. Greedy decoding (temp 0) is fully deterministic on this hardware: 20 runs at a fixed seed are byte-identical, so pass^k and variance are degenerate. pass^k only means anything under stochastic sampling. We run at temperature 0.7 with a fixed seed set (0–19, identical across configs), so within-config variance is real and configs stay comparable. The backend filesystem state is fully reset between runs.
Defensive parsing, raw output logged. Tool calls are parsed client-side from the model's native format (Qwen <tool_call> tags; Llama <|python_tag|> JSON, including its {call1}; {call2} multi-call form). When the model deviates from its native format and we recover the call from prose or a fenced block, the run is recorded as parse_recovery_triggered — a failure sub-category, never silently counted as a pass.
Completion oracle. Each task ships BFCL's initial_config (backend state) and a ground-truth call sequence. We execute the model's calls and the ground-truth calls against fresh GorillaFileSystem instances and compare state with BFCL's verbatim state_checker. The eight tasks span simple dispatch, multi-step chaining, ambiguous tool selection, restraint (correctly not calling a withheld tool), and missing-parameter handling — including BFCL's faithful tool-holdout mechanism.
Failure taxonomy. Every non-success run is classified into exactly one mode: right_tool_wrong_args, wrong_tool, hallucinated_tool, tool_call_loop, failure_to_stop, malformed_json, or parse_recovery_triggered. Rule-based, over the logged raw output, independently auditable.
Results
The matrix
Per-task end-to-end completion rate (n=20 each):
| task (category) | qwen-4bit | qwen-8bit | llama-4bit | llama-8bit |
|---|---|---|---|---|
base_25 (ambiguous tool) | 100% | 90% | 40% | 80% |
base_3 (simple dispatch) | 95% | 80% | 0% | 0% |
miss_func_9 (restraint) | 5% | 0% | 0% | 0% |
base_6 (chaining) | 0% | 0% | 0% | 0% |
base_10 (chaining) | 0% | 0% | 0% | 0% |
miss_func_37 (restraint) | 0% | 0% | 0% | 0% |
miss_param_16 (ambig. params) | 0% | 0% | 0% | 0% |
miss_param_29 (ambig. params) | 0% | 0% | 0% | 0% |
Config-level completion, with Wilson 95% intervals and served peak memory:
| config | completion | Wilson 95% | peak mem |
|---|---|---|---|
| qwen-4bit | 25.0% | [0.19, 0.32] | 48 GB |
| qwen-8bit | 21.2% | [0.16, 0.28] | 84 GB |
| llama-8bit | 10.0% | [0.06, 0.16] | 78 GB |
| llama-4bit | 5.0% | [0.03, 0.10] | 42 GB |
Memory doesn't predict reliability
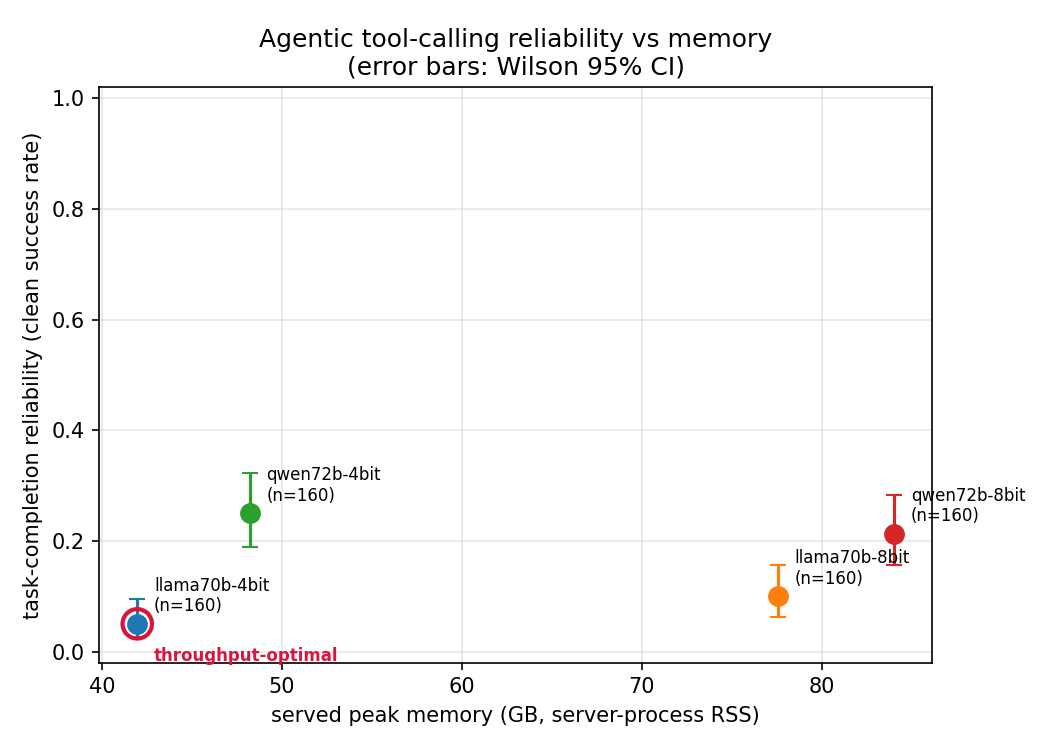
llama-4bit and qwen-4bit differ by 6 GB of footprint and 5× in reliability. A memory- or throughput-oriented benchmark would rank them as near-peers; end-to-end completion ranks Qwen-4bit first and Llama-4bit last. The memory-optimal config (the smallest, llama-4bit) is the least reliable — the exact "throughput says X, reliability says Y" gap this series exists to surface. On the headline plot, qwen-4bit sits top-left and dominates everything.
The quant effect flips by family
The discriminating cells, with pass^k:
| qwen-4bit | qwen-8bit | llama-4bit | llama-8bit | |
|---|---|---|---|---|
base_3 per-run | 95% | 80% | 0% | 0% |
base_3 pass^5 | 0.75 | 0.28 | 0.00 | 0.00 |
base_25 per-run | 100% | 90% | 40% | 80% |
base_25 pass^5 | 1.00 | 0.55 | 0.00 | 0.28 |
For Qwen, 4-bit dominates 8-bit — and pass^k makes it stark. On base_3, 95% vs 80% per-run looks like a modest gap; pass^5 of 0.75 vs 0.28 says that if your workflow needs five consecutive successes, 4-bit delivers them 2.7× as often. 8-bit pays 1.75× the memory to be less reliable.
For Llama, 8-bit dominates 4-bit — the opposite direction. base_25 goes 40% → 80% (per-run) and 0.00 → 0.28 (pass^5) moving from 4-bit to 8-bit. So there is no model-agnostic rule: the same intervention (more weight precision) helps one family and hurts the other.
Why: 8-bit suppresses Llama's tool-call loops
The failure taxonomy explains the flip. Per-config failure counts (out of 160):
| mode | qwen-4 | qwen-8 | llama-4 | llama-8 |
|---|---|---|---|---|
| success | 40 | 34 | 8 | 16 |
| right_tool_wrong_args | 58 | 57 | 12 | 66 |
| wrong_tool | 28 | 24 | 48 | 50 |
| tool_call_loop | 13 | 12 | 62 | 13 |
| hallucinated_tool | 20 | 30 | 19 | 4 |
| failure_to_stop | 0 | 1 | 3 | 8 |
| malformed_json | 0 | 0 | 7 | 2 |
| parse_recovery_triggered | 1 | 2 | 1 | 1 |
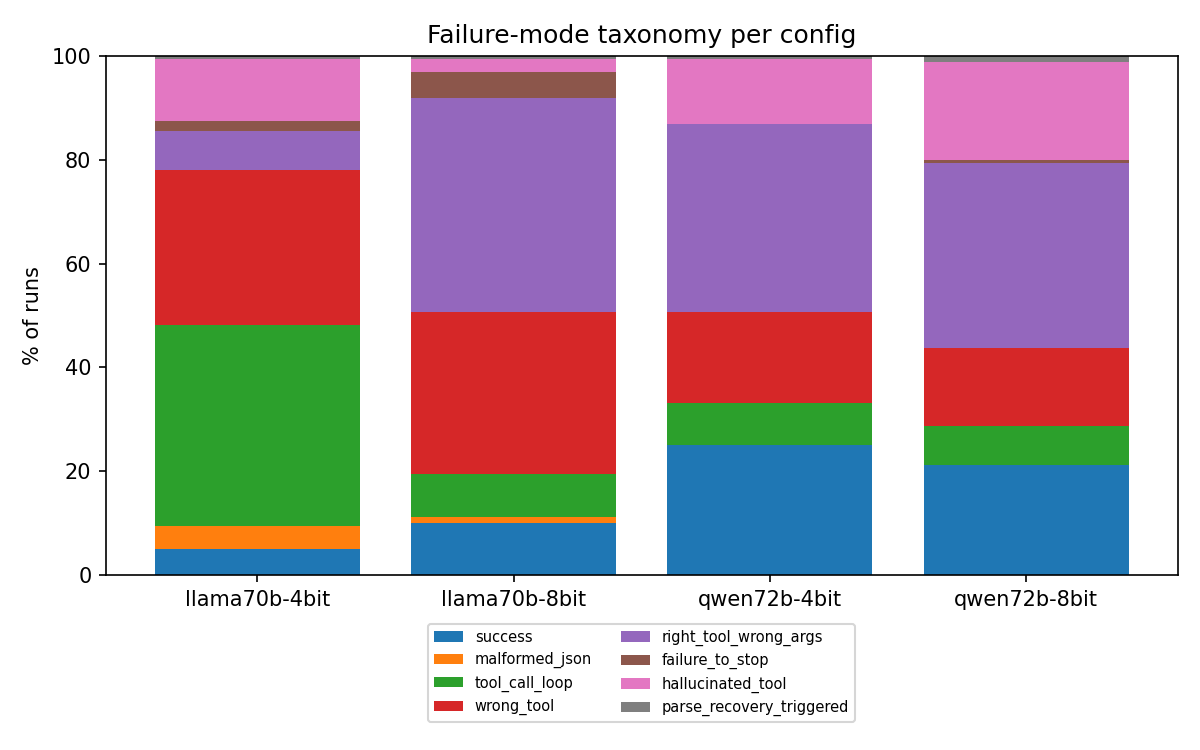
Llama-4bit's dominant failure is degenerate looping — 62 of 160 runs call the same tool over and over until the step cap. Going to 8-bit collapses that to 13 and moves the mass into right_tool_wrong_args (12 → 66): the model now picks the right tool and merely gets an argument or a navigation step wrong — near-misses instead of catastrophic loops. That is where Llama's reliability gain comes from. Qwen never had the loop problem (13 / 12 at either width), so 8-bit has no loop to fix; it slightly raises hallucinated_tool (20 → 30) and lowers success.
The dominant failure mode overall is right_tool_wrong_args, and it has one overwhelming concrete cause. Auditing the first failing turn of all 193 right_tool_wrong_args episodes, 153 (79%) are the same mistake: the model skips a ground-truth cd and operates on the file in the wrong working directory (e.g. ground truth cd; cd; cp; cp, the model emits just cp; cp). That single missing navigation step is what floors the multi-step chaining tasks (base_6, base_10) for every config.
What broke and what didn't
This study changed shape twice, both times because of how mlx_lm.server handles tools.
mlx_lm.servercannot return raw tool output. Its completion handler unconditionally parses tool calls out of the model text, empties thetextfield, and runs them through a parser that doesjson.loads(text.strip())— which crashes on multi-call or messy output. On a first pilot, ~9% of the restraint-task runs crashed the request and were logged as transport errors, losing the raw output we are required to keep. We moved generation in-process. This also fixed peak-memory measurement (in-processmx.get_peak_memoryinstead of polling a server process's RSS).- Temp 0 made
pass^kmeaningless. The first pilot at temperature 0 was perfectly reproducible — 20 identical runs, zero variance. We switched to temperature 0.7 with a fixed seed set. - The parser had to be hardened against real output, not assumptions. Two bugs, both caught by auditing data rather than trusting green tests: (1) a prose final answer containing a markdown code fence was mis-flagged as a recovered/malformed tool call, inflating
parse_recovery_triggeredto 53% of runs before the fix; (2) Llama emits multiple calls in one turn as{call1}; {call2}and prefixes prose answers with<|python_tag|>, neither of which a singlejson.loadshandles. Because raw output is logged, the first was corrected offline with no re-run; the second changed which calls executed, so Llama was re-run. - What didn't break: the state-based completion oracle (BFCL's verbatim
state_checker), the ≥20-runs-per-cell discipline, the append-only durable logging, and the resumable sweep (the Llama run survived two restarts without losing or duplicating work).
What we're not claiming
- Not a leaderboard. Eight GorillaFileSystem-only tasks are a deliberately narrow, auditable slice of BFCL multi-turn — enough to make the harness honest, not enough to rank models in general.
- Thin dynamic range. Five of eight tasks floor at 0% for all four configs; the discriminating signal is
base_3andbase_25. The config-level Llama intervals overlap ([0.03, 0.10] vs [0.06, 0.16]); the 8-bit > 4-bit claim for Llama rests onbase_25and the loop-count mechanism, not the overall rate alone. - Single domain, single suite, single seed set. Filesystem tasks only; no τ-bench user-simulator arm yet; no constrained decoding yet.
- Provenance footnote. The Qwen rows were generated before the final parser version; re-parsing the stored raw output shows the difference touches 29 steps across 18 episodes, all in tasks that score 0% for both Qwen configs, and zero in the discriminating cells. The within-Qwen and within-Llama comparisons are exact; the cross-family comparison carries this footnote.
Comparison to prior art
arXiv 2505.19433 finds, for ≤32B models on T-Eval-style competency, that quantization's effect on tool-use is small and not monotonic in bit width. Our large-model, end-to-end-completion result is consistent in spirit — bit width is not a simple "more is better" dial — but sharper in two ways. First, the effect is not just non-monotonic, it reverses sign across families (4-bit best for Qwen, 8-bit best for Llama). Second, measuring task completion with pass^k rather than single-call competency surfaces gaps that per-call metrics miss: an 80%-per-call config can be a 0.28-pass^5 config.
Reproducing
git clone https://github.com/abhiram304/mlx-dense-bench
cd mlx-dense-bench
python -m venv .venv && source .venv/bin/activate
pip install -r requirements.lock
cd agent-reliability
# Quick wiring check — no 70B weights needed (pulls a 1.5B model from HF):
python run.py smoke configs/smoke_tiny.json
# 1. build the four quant artifacts from base HF weights (records SHA + command)
python quantize.py # ~285 GB download + convert, one-time
# 2. the full sweep: 4 configs x 8 tasks x 20 seeds (resumable, ~2 days on M3 Ultra)
python run.py sweep configs/sweep_phase1.json
# 3. gate + figures
python run.py validate results/runs.jsonl # fails any cell with n < 20
python plots.py results/runs.jsonl results/manifest.jsonl results/plots
Tasks are vendored as versioned JSON (tasks/) with BFCL provenance; the deterministic completion oracle is unit-tested without any model.
Colophon
| Hardware | Mac Studio M3 Ultra, 512 GB unified memory |
| OS | macOS 26.2 (arm64) |
| Runtime | mlx 0.31.1, mlx-lm 0.31.2 |
| Models | Qwen-2.5-72B-Instruct, Llama-3.1-70B-Instruct |
| Quant | self-built via mlx_lm.convert, affine, group size 64 (bit width is the only within-family variable) |
| Task suite | BFCL v4 multi-turn (gorilla 6ea5797), GorillaFileSystem-only, 8 tasks |
| Episodes | 4 configs × 8 tasks × 20 seeds = 640, n=20 per cell |
| Wall-clock | ~2 days, resumable across restarts |
| License | see LICENSE in the public repo |
| Public artifacts | github.com/abhiram304/mlx-dense-bench (harness under agent-reliability/, configs, results JSONL, figures) |
Every run row carries its manifest (model SHA, versions, peak memory), and raw model output is retained per turn for audit.
Citation
@misc{salammagari2026densebench4,
author = {Salammagari, Abhi Ram and Salammagari, Koushik},
title = {Dense Bench, Part 4: agentic tool-calling reliability vs weight quantization},
year = {2026},
url = {https://www.abhiramsalammagari.com/writing/dense-bench-4-agentic-tool-calling-reliability},
note = {harness: \url{https://github.com/abhiram304/mlx-dense-bench}}
}
~~~